1. Background
My recent compositional practice has incorporated spoken word into concert music. In the last seven years only three short chamber pieces have been written without text; the bulk of my output has included text, in the form of spoken word. Speech has been incorporated in various ways: it has been distorted into metrical rhythms in ANIMA (2009) and The Revenge of Miguel Cotto (2012); it has been recited freely as poetry alongside instrumental music in Numbers 91–95 (2011) and Romanticism (2012); text has been spoken in groups, drawing on the German Sprechchor tradition in Socialist Fucking Realism (2013) and Numbers 76–80 (2011); and text has been cut and spliced into streams of consciousness in Illusions (2015) and Unleashed (2012). Source texts for these pieces have ranged from contemporary British poetry to verbatim interview transcripts, to excerpts of Hansard to liturgical text, to footage of a drag performer’s improvised rant.
The decision to develop this practice can be broken down into two steps: first, the decision to include text in musical works, and second, the decision to deliver that text through the medium of speech, rather than, for example, singing. Clearly these are interdependent decisions, but both are based on a key objective for the audience experiences that I make: immediacy. That can be applied to those two decisions as semantic immediacy (by using text) and immediacy of comprehension (by using speech). It is important to discuss these two ideas before moving onto a discussion of spoken word in opera.
Text affords semantic immediacy in a way that music alone cannot, because text can present concrete, specific ideas. If we assume that the mode of text delivery is itself immediately comprehensible (which will be discussed in the next paragraph), then these concrete ideas can be presented and digested by the audience in a split second, in real time, as the text (and music) goes by. Whether by reading or listening to speech or thinking sentences, words and their meaning can be processed immediately by an audience. In contrast, musical form is often understood retrospectively – the significance or meaning of phrases within the context of form makes sense only once we have heard the entire piece. Musical grammar and syntax often requires time to absorb, digest and interpret, and its meanings and form are, of course, not semantic, but something other. Therefore, combining text with music gives the composer a larger toolbox with which to create meaning and signpost form, perhaps with a semantic form/language and musical form/language co-existing independently.
Given the decision to incorporate text, the second decision is how that text should be presented – the mode of delivery. The most common mode of text delivery in most musical genres is singing. However, there are good reasons for exploring alternatives to sung text. Speech or other non-sung text on stage often achieves greater semantic impact than sung text; the audience understands more of it. It is an interesting paradox that spoken text has less expressive power (as opposed to narrative power) compared to sung text: in a sung line, the complexity of the vocal line and semantic comprehension are often in direct conflict. In most cases, when the musical line becomes more complex (e.g. melismatic aria, or high tessitura), semantic comprehension is lost, and when semantic comprehension is favoured, vocal expressivity is usually forfeited (e.g. recitative). Not only that, but the more a text is contorted away from natural speech patterns in order to fit a complex sung line, the more destruction is wrought on any poetic meter or form in the text.
The alternative, as I have explored in previous concert works, is to present spoken text alongside music. The spoken text provides semantic immediacy and linguistic grammar/form, and the music provides expressivity and musical form. The performance of spoken text provides another sonic layer to the work, and brings with it a heritage of spoken theatre and poetry performance that can be mined for inspiration. The composer then has the opportunity to develop techniques to work with speech as compositional material in itself, and may use such tools as fragmentation, repetition, text variation, re-ordering, dynamics and performance directions, much as he/she would with musical material.
This research seeks to develop such non-sung modes of text delivery, and put them to work in opera. Opera is a music-led performance form, and as such, like other performance forms such as theatre and dance, opera seeks to tell stories. Stories can be told on stage without text, of course, such as Stockhausen’s second act of Donnerstag aus Licht (1980) – Michaels Reise um die Erde, an opera without words or voice, or the tradition of french mime, or Stravinsky and Nijinsky’s The Rite of Spring (1913), or more recently, David Sawer’s Rumpelstiltskin (2009) – all stories told in movement and music. However, it is more common than not for operas to tell stories using text, and so given the presence of a text, opera makers must choose how to deliver it. Generally, the accepted consensus is that theatre chooses mainly spoken text and opera chooses mainly sung text. One is driven by the rhythm of words, one by the rhythm of music. But between these two traditions lies a whole spectrum of fertile ground for opera- and theatre-makers to cultivate: spoken-word theatre that is driven by music, music that is driven by the rhythm of text, combinations of song and speech and everything in between, the full spectrum of semantic comprehension independent of musical expressivity, text and music in a constant jostle for primacy. What defines opera apart from theatre is the dominant presence of music – everything else is up for grabs.
There are, naturally, many artists working this fertile ground, each ploughing their own particular furrows of enquiry. The most common examples of spoken text with music are found in character-narrative film and spoken theatre, whereby a speech may be given freely over the top of live or recorded music. For example, Walton’s Passacaglia in his music for Laurence Olivier’s 1944 film of Shakespeare’s Henry V is played alongside the delivery of Henry IV’s speech “I know thee not old man”, even though we see only Falstaff on screen and hear Henry IV’s voice in the distance, off-screen (the distance indicated by the applied reverb on the spoken voice).
In the world of opera, there are works that lightly pepper an otherwise completely sung drama with short, spoken-word interjections or interludes. Mark Anthony Turnage and Jonathan Moore’s opera Greek (1988) does this, whereby characters deliver short spoken-word speeches free from specified musical pulse or melody, and sometimes without musical accompaniment. Figure 1 shows an excerpt of Olga Neuwirth and Elfriede Jelinek’s opera Lost Highway (2003), based on the David Lynch film (1997) of the same name. This opera is scored for a mixture of actors and singers, and contains extended passages of freely-spoken text, sometimes unaccompanied and sometimes juxtaposed over music.

Figure 1: An excerpt of Scene 1 of Lost Highway (2003) by Olga Neuwirth, showing freely spoken text over the top of pre-recorded and live music
The effect of this moves the piece more towards a theatre genre, and in this case references the spoken-word format of the original film. With a mixed cast and so much spoken word over the top of music, we could consider this a juxtaposition of theatre and opera. The proportion of spoken word versus singing is pushed even further in Einstein on the Beach (1976) by Philip Glass and Robert Wilson, which has solo roles for actors and for singers, and entire scenes that consist of only spoken text, over a musical background. Similarly, Beat Furrer’s FAMA (2005), for actor, chorus and ensemble, features only spoken text for the actor, juxtaposed over the permanent presence of music; Furrer describes this as ‘Hörtheater’ – a neologism roughly translated as ‘theatre of the ears’.
Unlike these examples of freely-spoken text superimposed without precise coordination over a musical landscape, there are others where the speech itself is subjected to contortions of musical pulse and pitch. The rhythmicization of spoken text can be found in a simple form in William Walton and Edith Sitwell’s ‘entertainment’ Façade (1951), where spoken text is written in simple musical meters of mainly crotchets and quavers. The complex natural speech rhythms are contorted to fit into simple musical rhythms – simple enough to be performed frequently by untrained voices.
This approach can also be applied to a ‘Sprechchor’ (speaking chorus) such as the untrained voices (but musically trained brains) of an entire orchestra, who speak words and speech-like sounds/syllables in György Ligeti and Michael Meschke’s Le Grande Macabre (1977, rev. 1996), as shown in the excerpt in Figure 2.

Figure 2: An excerpt from Ligeti’s Le Grande Macabre (1996) showing speech sounds delivered by string players with non-trained voices.
In a similar fashion, Harrison Birtwistle and David Harsent used more complex rhythms for a trained spoken chorus on stage in Scene 7 of The Minotaur (2008). The gang of Keres (the harpies) speak in unison in notated rhythms and repetitive patterns: “bloodshed fetches us, slaughter fetches us, starved for blood, ravenous for blood”. These rhythms are aligned with the musical pulse and rhythms of the orchestral writing, although they do not specify pitch.
In addition to rhythmic contortions of spoken text, other composers specify pitch patterns too. Enno Poppe’s Interzone (2004), after William Borroughs, contains a solo role for male speaker that covers everything from unaccompanied freely-spoken text in the introduction “Like Spain, I am bound to the past” to intricate indications of pitch and rhythm in spoken word at the end of Part 1 “It’s Man or Monkey” (see Figure 3) that are much more complex than in Façade. However, even when Poppe’s spoken text is most distorted from its natural rhythm and pitch, it does not quite cross the boundary into trained singing: the performer is described as an actor (although specified as a baritone), the pitch specifications are approximate, and the more specified passages still retain a feeling of strangely mechanized or contorted speech, rather than ‘operatic’ singing. (There is trained singing in Interzone, in the form of a quintet (SMACtB) performing chorus and solo roles.)

Figure 3: An excerpt of It’s Man or Monkey from Enno Poppe’s Interzone, showing the Speaker with complex rhythmic and pitch indications
However, pitch specifications for ‘speech’ can and do cross that boundary into trained singing. For example, the role of Moses in Schoenberg’s Moses und Aron (1932) is described as a speaking role, but one in which both general pitch and specific rhythm is defined by Schoenberg, hence moving the role more towards sprechstimme and therefore more often performed by a trained singer using their trained voice.
Such techniques are not confined to material for live performance. Other artists play with pre-recorded spoken text, ranging from a simple pre-recorded voiceover without coordination with a musical layer, to finely-crafted rhythmic collages of fragments of audio material. Pre-recorded voiceover appears in another Birtwistle opera The Mask of Orpheus (1984), where the spoken voice of Apollo is heard only on recording, played into the auditorium. Outside of conventional character-driven narrative, theatre-makers have explored pre-recorded voiceover as a way of articulating a third-party point of view, not tied to a character. For example, Katie Mitchell and Alice Birch’s Ophelias Zimmer (2015) features five interludes that use pre-recorded spoken text describing in the third person the physiological stages of drowning (this is discussed further in Chapter 5 – Voiceover).
The above examples feature spoken text that has a primarily semantic function – it is there to impart linguistic meaning, from various dramaturgical points of view. However, spoken text for live performance may also be subjected to fragmentation, repetition and re-ordering, in the same way that a composer might treat melodic material. Often, just like musical material, such operations may use spoken text to create form/shape that is independent from the linguistic shape of the text. Georges Aperghis, for example, treated text fragments to repetition and re-ordering in his Recitations (1978) for solo voice. Recitation 11 takes this text (fragments separated by slashes):
Ça doit / ainsi / bon / un peu tard / d’ici / ça! / Madame / Je / c’est / ça s’ecrit / comment? / nuit dernière / (rire) / Je veux que / Je m’excuse / C’en est un / Faut pas vous appeler/ Comme ca! / va lui demander toi / et puis? / gramme / par gramme / Rien qu’à moi19 / tu n’auras / soeur de ton / Ha / Rien / suis / Ha Ha! / pour les / Gens / comment / Moi? / Non! / à la / precieuse
Aperghis, G. Recitation 11 (1978)
(rire) = a performance instruction, to laugh
The 36 fragments are centred on Comme ça! (underlined), and around this axis the fragments are introduced two at a time either side of the central Comme ça!, until all 36 are performed in sequence. The score clearly illustrates this structural approach to repetition and ordering, shown in Figure 4.

Figure 4: Recitation 11 (1978) by Aperghis, showing the structuralist / formalistic approach to repetition and ordering. The word moi changes to toi mid-way through the piece.
A much freer approach to fragmentation to create a kind of ‘stream of consciousness’ can be found in the work of Beckett. This is clearly visible in Not I (1972). Here is the first of five sections:
…. out… into this world… this world… tiny little thing… before its time… in a godfor-… what?.. girl?.. yes… tiny little girl… into this… out into this… before her time… godforsaken hole called… called… no matter… parents unknown… unheard of… he having vanished… thin air… no sooner buttoned up his breeches… she similarly… eight months later… almost to the tick… so no love… spared that… no love such as normally vented on the… speechless infant… in the home… no… nor indeed for that matter any of any kind… no love of any kind… at any subsequent stage… so typical affair… nothing of any note till coming up to sixty when-… what?.. seventy?.. good God!.. coming up to seventy… wandering in a field… looking aimlessly for cowslips… to make a ball… a few steps then stop… stare into space… then on… a few more… stop and stare again… so on… drifting around… when suddenly… gradually… all went out… all that early April morning light… and she found herself in the… what?.. who?.. no!.. she!..
Beckett, S. Not I (1972)
The ‘…‘ indicate very short pauses or breaths. Motifs are repeated between the four sections, for example ‘what?.. who?.. no!.. she!..’ finishes each section but the last. Other circumlocutions throughout the text include ‘good God!’ and ‘tiny little thing’ and ‘April morning’ and references to the mouth and speech. The scatter-gun, stream-of-consciousness effect is clear, especially when delivered in very fast, exasperated speech.
However, the stream of consciousness is made entirely intuitively; there is no pattern to the repetition, fragmentation or ordering of phrases, unlike the Aperghis approach. In a musical analogy of Beckett’s stream of consciousness, Luciano Berio’s well-known third movement to Sinfonia (1969) – In ruhig fliessender Bewegung – subjects excerpts of another Beckett text, his novel The Unnamable (1953), to extensive fragmentation and collage techniques, delivered through spoken text in live performance with eight vocalists, accompanied by orchestra. This collage technique is also applied to the music, drawing in many musical references, in what is perhaps the most well-known example of a musical ‘stream of consciousness’.
Berio has taken fragmentation, distortion and layering of spoken text to such extremes that semantic meaning is no longer comprehensible, but the work is still articulated in the form of speech sounds (rather than a sung voice).
In these cases, where semantic meaning is lost, the speech sounds become musical material like any other; the semantic structures and immediacy of comprehension, which were discussed earlier, are lost. This has been described as ‘paralinguistic text’ (Stacey, 1989). Berio pioneered such techniques, often to build highly-complex textures, in works such as Sequenza III (1965), Laborintus II (1965) and A-Ronne (1975), and continued by others such as Beat Furrer in Begehren (2003). Figure 5 shows an excerpt of Laborintus II, showing a complex, rich texture made from spoken words, but so dense that individual lines are not semantically comprehensible.
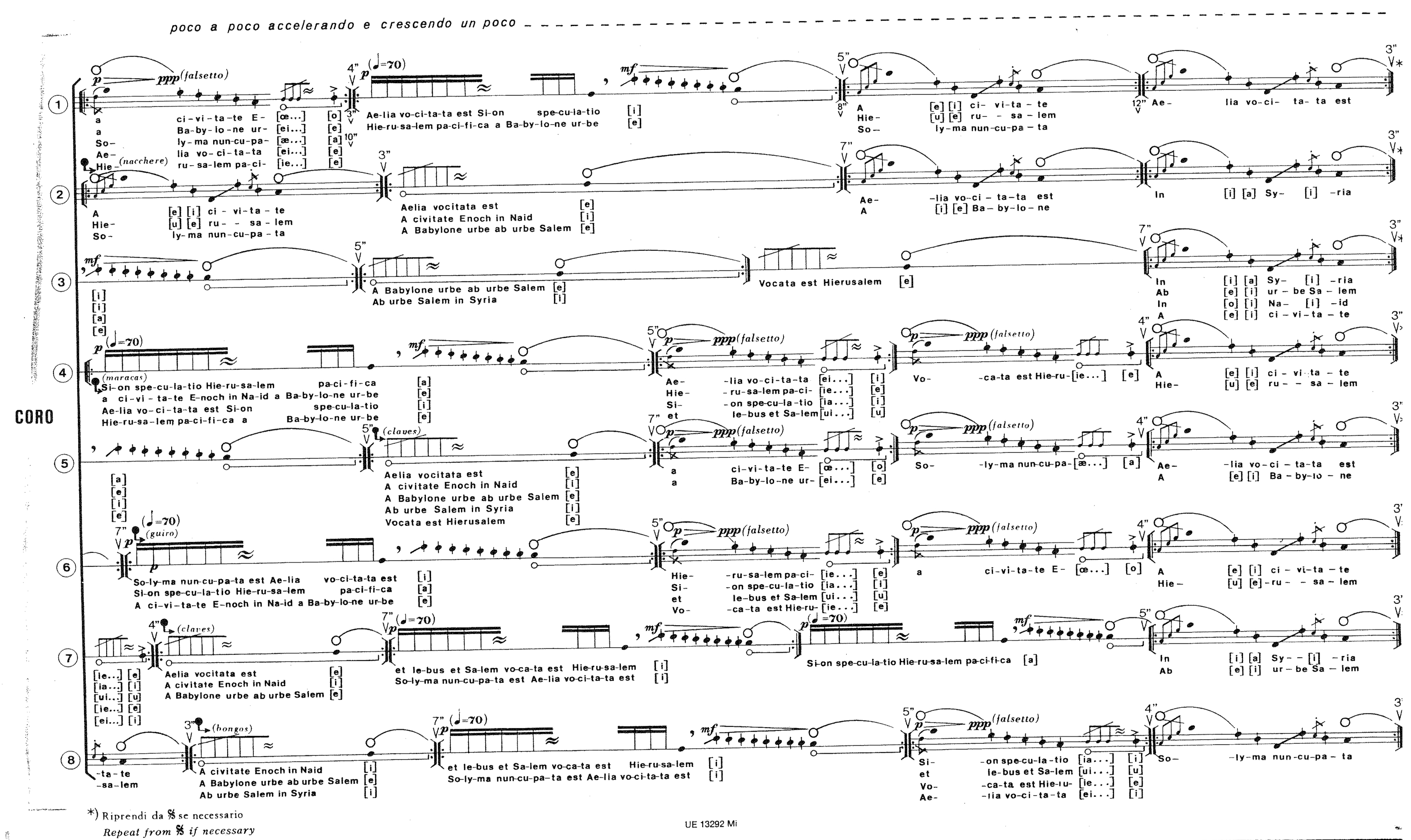
Figure 5: An excerpt of vocal writing in Berio’s Laborintus II (1965), showing layering of many speech fragments
Just as the examples of composers who have contorted and fragmented speech for live performance, such contortion, fragmentation and repetition can be practised also with recorded audio. A simple early example would be Steve Reich’s It’s gonna rain (1965), a piece for magnetic tape that takes a piece of found material, a recording of a street preacher from San Francisco, copies it across two tape loop machines (stereo left and right) and alters both the loop length and the phase difference between the two recorders, creating shifting delay between the two loops. This creates a hocketing of the sentence ‘It’s gonna rain‘ between the two channels. Reich’s work with pre-recorded speech took a step further in Different Trains (1988), in which interviews with people about train journeys were cut up into small soundbites, and then the pitch and rhythm of the spoken phrases were transcribed into music for multiple string quartets (three pre-recorded and one live). Reich then subjected both tape material and string quartet material to a series of repetitions, syncopations and imitations; so much so that in performance it is hard to tell what is imitating what. Neither text nor music has primacy.
Techniques such as tape-cutting and looping pioneered by Reich and others later extended into DJs’ work with vinyl scratching and digital editing techniques of electronic music artists. For example, Frontier Psychiatrist, from the debut album Since I left you (2000) of Australian DJ quintet The Avalanches, is a virtuosic mash-up of spoken-word samples, constructing new sentences out of very short samples from a variety of different spoken-word and musical sources. They do this using a mixture of turntable techniques (scratching, stuttering, speed alteration) and digital techniques (cutting, splicing, copying, pasting). The second verse of Frontier Psychiatrist, beginning at 1’33”, uses 19 spoken-word samples from different sources to construct the lyrics for this verse, lasting 27 seconds (discontiguous samples are here marked by a slash and the ‘stuttering’ is written out):
Avalanches above, business continues below /
Did I ever tell you the story about / [scratch]
Cowboys / mi–mi–midgets / and / the indians / and / Fron–Frontier Psychiatrist /
I – I – I felt strangely hypnotised / [scratch]
I was in another world, a world of / 20–[scratch]–20.000 girls /
And milk! / and rectangles / to an optometrist / the man with the golden / eyeball /
And tighten your buttocks / pour juice on your chin /
I promised my girlfriend I’d / hit the violin–violin–violin–violin…
[into Walton’s Spitfire Fugue]
Similar sampling techniques have been used by the satirical video artist duo Cassetteboy, inspired by analogue tape-cutting techniques rather than turntable scratching. Their work consists of reconstructed speeches by one orator, constructed of samples taken from multiple speeches by that person. They may construct these artificial speeches on a musical framework, for example to make alternative lyrics for a pop song (see this example Gettin’ piggy with it, a cover version of Will Smith’s Gettin’ jiggy wit it). Or they construct speeches without such musical backing, but mimicking natural speech rhythms so carefully that the editing joins are sometimes undetectable (see the this video from the Cassetteboy remix the news series).
1.1. Research Objectives
The discussion above has outlined how my practice and the work of other artists have involved spoken word, using various techniques for both live performance and pre-recorded material. These techniques will be extended into opera – a new direction for my own practice – to address the following research objectives.
- To explore techniques to incorporate spoken text into opera, both live and pre-recorded:
- Voiceover techniques;
- ‘Stream-of-consciousness’ – Fragmentation, repetition, re-ordering, imitation, collage;
- To incorporate speech into sung lines.
- To explore visually-presented text in opera, placing it within a musical framework.
(A discussion of others’ work in the field of visually-presented text and music will be discussed in Chapter 8 – Percussion Dialogues.) - To explore the dramaturgical implications of these two objectives.
These objectives ultimately contribute to the overall objective discussed at the beginning of this chapter: to make an opera that has semantic/linguistic immediacy, and where the source text is equally present alongside the music.
These research objectives guided the choice of source text for this opera, Sarah Kane’s 4.48 Psychosis. Since the objectives above have an impact on dramaturgy, the next chapter will explain this choice of source text and give a brief analysis of it.